JILT 1996 (2) - Pasha & Soper
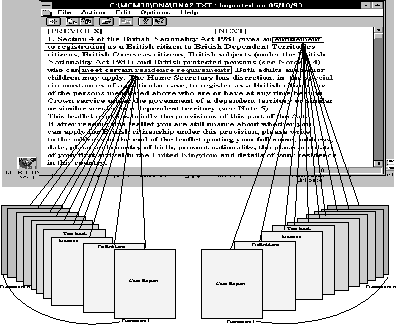
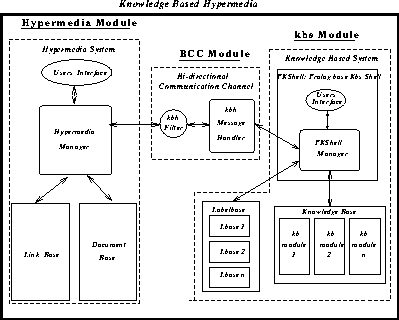
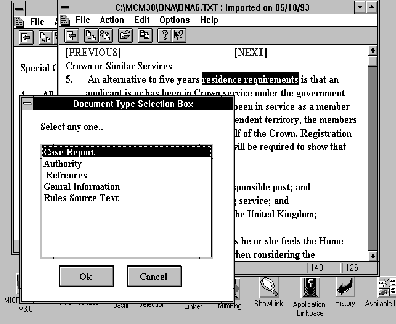
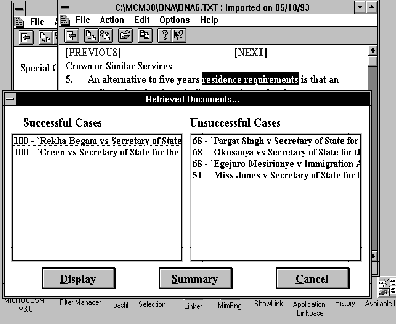
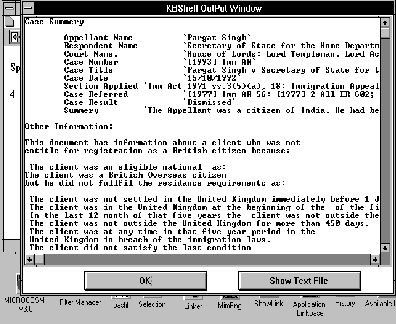
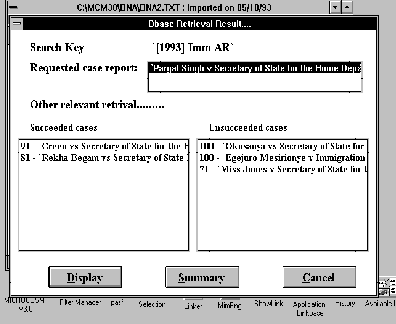
Combining the Strengths of Information Management Technologies to Meet the Needs of Legal Professionals M. A. Pasha and P. J. Soper Contents Abstract The availability of a burgeoning quantity of on-line legal information and the present trend of computer usage in legal practice have created a pressing need for practical systems which can retrieve required pieces of information in a precise fashion and support the use of the retrieved information in legal practice. This paper attempts to address these needs by combining the strengths of two contrasting technologies: hypermedia whose strength is in handling unstructured information; and kbs whose strength is in handling structured information. More particularly we describe a logic programming based information management tool which provides the infrastructure for conceptual retrieval within this combined framework. The tool is applied to three needs of legal professionals: precise information retrieval; practical use of the information retrieved; and support for open texture interpretation. This is a Refereed Article published on 7 May 1996. Citation: Pasha M A and Soper P (1996) 'Combining the Strengths of Information Management Technologies to Meet the Needs of Legal Professionals', 1996 (2) The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/elj/jilt/itpract/2pasha/>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1996_2/pasha/> The availability of a burgeoning quantity of on-line legal information and the growing interest in computer usage in legal practice are two obvious outcomes of current advances in computer and multimedia technologies. This has introduced a twofold need: firstly, for systems to retrieve only, or at least rather precisely, the required pieces of information; secondly for software tools which can support the use of the information in legal practice. The key point here is that legal users are interested in specific retrieval for specific purposes and therefore they need tools for these practical purposes [ Greenleaf et al. 1991 ]. Another important aspect of the present situation is that hypermedia is becoming the dominant style of information management in the legal domain, as in other domains [ Yoder & Wettach 1989 ], [ Agosti et al. 1991 ], [ Terrett 1994 ]. In hypermedia systems relevant pieces of information are interconnected through links and required pieces of information are then accessed through activating these links. These systems offer a practical solution to the time consuming and painstaking problem of accessing cross references which is a distinctive feature of legal information. Furthermore it seems to be clear that the technology is being taken up rapidly. For these reasons this paper tries to address the needs of legal professionals by providing information management tools which support information held in hypermedia style. To put this in context we start, in Section 2, by describing some of the main limitations of current hypermedia systems for managing information in the legal domain. Regarding information retrieval, an important routine task of law practitioners is to find suitable cases, which can be referred to in court to make their argumentation strong. Before starting a search for suitable case reports, practitioners have a legal issue and their client's factual situation in mind. During the search they try to find cases related to a particular issue which has been decided under similar circumstances. In addition to this they also consider some other factors including whether they are arguing for or against the result indicated by legal rules, whether the point at the issue has been decided in ones favour or not in a precedent, and whether there are alternative paths to the desired result [ Skalak & Rissland 1991 ]. Retrieval of suitable cases for these purposes is an important issue in computer based legal research. Two well cited difficulties are query formation [ Bing 1988 ] and irrelevant retrieval [ Blair & Maron 1985 ], [ Gelbart & Smith 1991 ], [ Faloutsos & Oard 1995 ]. Researchers from the law and information retrieval communities are striving to overcome these problems. Some examples from current attempts are [ Greenleaf et al. 1991 ], [ Gelbart & Smith 1991 ], [ Mulder et al. 1993 ], [ Hearst 1994 ], [ Daniels & Rissland 1995 ], [ Mulder & Combrink-Kuiters 1996 ]. However, the results of these studies show that the problem has not been resolved yet. So precise retrieval is still an important need of of legal professionals. To apply retrieved, unstructured information for useful purposes the user, in general, specialises the information in some way to suit their particular purposes. If the system is to support such activities it must in some way help with the interpretation of the unstructured information. Currently advice systems, typically expert or knowledge based systems, are commonly used for such purposes. However, user-system interaction and knowledge base development are two well cited problems of such systems [ Allen & Saxon 1987 ], [ Barragan & Barragan 1991 ], [ Soper & Bench-Capon 1994 ]. Also users are unable to see the details of the primary source information used to solve their problem. The need is for systems which, on the one hand, allow users to see the practicality of the information, and, on the other hand, allow users to see the details of the primary sources. This paper will propose a solution to these problems which relies on combining advice systems with hypermedia technology. This fits in with Guy Vandenberghe's [ Vandenberghe 1990 ] picture of future legal information management systems. In his opinion one of the essential aspects of those future systems will be the integration of the various possible applications of computers in law, such as word processing, office automation, legal text retrieval and legal expert systems. In contrast most commercial applications have concentrated on only one of these aspects [ Greenleaf et al. 1991 ] and the legal professionals' need of such integration has not been fully met. Another important problem in computerising and understanding legal information concerns the prevalence of open texture concepts in legal information. For example many concepts are not clearly defined, are not defined at all, or have unspoken expectation [ Skalak & Rissland 1991 ]. Legal concepts are also dynamic; their meanings change as they are applied from case to case [ Linzer 1988 ]. Even the logical connectors used in legal rules can be ambiguous, because their scope may not be clearly specified [ Allen & Saxon 1987 ]. Many approaches have been proposed for handling open texture, such as leaving open texture concepts undefined in logical models so that users may decide their interpretation [ Bench-Capon & Sergot 1988 ]; using prototypes [ McCarty 1980 ], [ Schlobhm & McCarty 1989 ]; using case patterns [ v.d.L. Gardner 1987 ]; matching case dimensions [ Ashley 1990 ]; combing a number of these approaches [ Sanders 1991 ]. The problem, however, has not been resolved [ Poulin et al. 1993 ]. In this paper we attempt to meet three needs; adequately precise retrieval, integration of technologies to make practical use of the information, and support for handling open texture concepts. Our proposal aims to meet these needs within the prevalent hypermedia style of on-line information management by providing kbs support tools. In Section 3 we describe our proposal, discuss our prototype general framework knowledge based hypermedia ( kbh ) which combines the two technologies, and compare with other related approaches. The basic enhancement to hypermedia which our kbh framework provides is a form of conceptual retrieval. We have a specific proposal for conceptual retrieval, called Proof-tree based Conceptual Retrieval (PCR), whose basic idea is discussed in Section 4. Our form of conceptual retrieval (PCR) provides a powerful infrastructure to support the needs of legal professionals to retrieve case reports and other relevant information and then use it for practical purposes. Section 5 describes how PCR works in the legal domain by illustrating rather precise retrieval of case reports and other information through PCR in the kbh framework. The next three sections of the paper describe briefly how our framework addresses the needs mentioned above. Section 6 discusses the enhancement of the retrieval procedure in the kbh framework through combining PCR with conventional database retrieval techniques. This makes the retrieval a practical tool. Section 7 explains how kbh meets the need for integration, allowing the practical use of information. Section 8 discusses how our system helps users interpret open texture concepts. Concluding remarks are given in Section 9. 2. Hypermedia Systems and their Limitations The basic idea of hypermedia systems has been around since 1945 when Vannever Bush, Scientific Advisor to Roosevelt, put it forward [ Bush 1945 ]. Bush proposed a system that would allow users to store books, records, communications and so on and to retrieve any portion of information quickly based on associated cross-references. It is the recent development of computer technology, however, that makes it possible to implement this idea. The aim of hypermedia systems is very simple and practical: to provide an effective and easy-to-use environment for integrating and managing on-line information.The on-line information can be of various kinds, some examples being text, bit map, video and sound. Users can link relevant pieces of information together so that the information can be traversed in later navigational sessions in a non-sequential fashion. (See [ Conklin 1987 ], [ Jonassen 1989 ], [ Nielsen 1990a ] for detailed account). In spite of the practical features of hypermedia systems, there are still many problems which remain unresolved. Examples are manual linking overhead and disorientation [ Conklin 1987 ], [ Halasz 1991 ], [ Nielsen 1990b ]. A number of navigational aids have been suggested in [ Nielsen 1990b ] to overcome the disorientation problem: facilities for backtracking, graphical display of relative position of the current node through global and local overview diagrams, creation of prominent landmarks, use of time stamps and foot prints, and history of traversal of nodes. Nevertheless disorentation remains a major problem for hypermedia systems [ Mahapatra & Courtney 1992 ], [ Fauth 1995 ]. Automatic hypertext construction [ Allan 1995 ] and dynamic linking [ Faloutsos et al. 1989 ], [ Fountain et al. 1990 ], [ Gloor 1991 ], [ Zhuoxun et al. 1992 ] are some current proposals for reducing manual linking overhead. Dynamic links do not have any fixed end-point, instead the linked documents being captured at runtime. As well as reducing manual linking, this offers a more flexible way of navigating through the information because links are generated on the fly according to the varying needs of users. The approaches taken in these studies are based on conventional retrieval techniques and therefore introduce the associated irrelevant retrieval problem. The legal domain offers various information sources such as leaflets, summaries, statutes and case reports. A typical hypermedia system does not allow splitting of the available information according to its source. All available information is linked with the selected node without making any distinction as shown in Figure 1 . The figure illustrates links from various sources to their corresponding nodes. Linking information from all available sources with a single node can easily lead to an overwhelming number of links to the node, even for one type of source such as case reports. Clearly users may have difficulty finding required pieces of information during a navigational session. The layered model approach, proposed in [ Agosti et al. 1991 ], [ Bruza & van der Weide 1992 ], claims to handle this problem, but, in practice, the problem is not so simple to solve. For example, it is obvious from the text of Figure 1 that for entitlement to registration the client must meet certain residence requirements . These again have many further conditions which need to be satisfied. At the same time case reports cover many other aspects like court decisions, clients' factual situation, cited cases and so on. So it will be difficult to decide how many and what layers are required to link a case report. At the same time introducing a large number of layers will not only make navigation complicated but will also reduce users' inclination to explore the information and increase the chances of getting lost. Layered models are not suitable for handling this kind of complex information. As Nielsen comments it is not possible to find out the usability of this kind of layer structure without knowing how many layers will be suitable [ Nielsen 1990b ]. The root of the problem is that hypermedia links do not have conceptual information about the contents of the linked documents, so systems are unable to compute associations between conceptually relevant documents dynamically. In most fielded hypermedia systems links are no more than a simple GOTOs [ Dam 1988 ]. These systems can only retrieve those documents which have predefined associations. This particular weakness of hypermedia links has been discussed by several authors [ Garg 1988 ], [ Bruza & van der Weide 1992 ]. It is a major limitation of current hypermedia systems, since most users are not interested in exploring hypermedia information spaces per se , but rather in obtaining information to solve problems or accomplish tasks [ Fischer et al. 1989 ], [ Greenleaf et al. 1991 ], [ Bench-Capon et al. 1991 ]. Legal professionals, for example, need a system which, on the one hand, analyses their request, compares it with the available data items and retrieves only those data items which are relevant to their request. They also need a system to help them in their routine tasks, such as decision making. The main point is that links need to depend on user needs rather than being predefined. We believe this goal can be achieved by combining the strength of hypermedia, whose strength is in handling unstructured information, and kbs, whose strengths are in handling structured information and offering a reasoning facility. In the next section we propose a new composite system, knowledge based hypermedia ( kbh ) [ Soper & Pasha 1994a ], [ Pasha 1996 ], that combines the kbs and hypermedia technologies and offers an effective and powerful environment to meet the needs of legal professionals. Knowledge based hypermedia ( kbh ) is a general purpose framework in which a logic programming (LP) based kbs and a hypermedia system are loosely coupled into a composite system. The two components of the system, the hypermedia manager and the kbs shell, communicate with each other through a message passing protocol on a run-time basis and remain independent entities. The main motivation for the development of this framework is to improve the performance of hypermedia systems and kbs's by loosely coupling them into a composite system. On the hypermedia side the presence of the kbs can enhance the functionalities of hypermedia systems and address some of their fundamental navigational and retrieval problems. On kbs side the presence of the hypermedia system can address some of the fundamental problems of user-system interaction associated with current kbs. A conceptual model of the kbh framework is shown in Figure 2 . It is implemented using a modular based open architecture approach which provides an alternative, and very flexible, way of introducing additional structure into hypermedia. The structure, which may concern a whole range of features from semantic support to text formatting, can be modelled in the kb. Because of the open architecture the resulting kbs component, which is being developed in an LP style, is composable with suitable present or future hypermedia systems. The kbh framework allows users to utilise the functionalities of hypermedia, kbs, or both together. The communication between the hypermedia and the kbs is established by introducing a new kind of link between hypermedia and knowledge base. In typical hypermedia links lead to other parts of the hypermedia. In the kbh framework links can also lead to the knowledge base. Such links gives rise to a query to the knowledge base via the kbs shell. Therefore, in the kbh framework, users can navigate through the whole body of information in the document base using the hypermedia manager's navigational tools and also can send queries to the kbs and receive responses. It will be noticed that the kb is divided into modules. This is because both different parts of the document base and different aspects of those parts can be modelled in different modules of the kb. Our main reason for selecting kbs and hypermedia technologies is that hypermedia is a powerful technology for on-line information management which is producing encouraging results. Furthermore it seems to be clear that the technology is being taken-up rapidly and so seems likely to be a front-runner in the future of information management. Apart from this pragmatic motivation, the advantages of kbs techniques in hypermedia have been widely recognised [ Marchionini & Shneiderman 1988 ], [ Minch 1989 ], [ Kibby & Mayes 1989 ], [ ElHani 1992 ], [ Soper & Pasha 1994b ], [ Pasha & Soper 1995 ]. Information retrieval systems (IRS) as a general technology for information management are not so attractive because they can not handle different media. But regardless of this, IRS is an essentially orthogonal technology which can be added in a straightforward way to both hypermedia and kbs [ Greenleaf et al. 1991 ], [ Fountain et al. 1990 ], [ Gloor 1991 ], [ Gelbart & Smith 1991 ], [ Daniels & Rissland 1995 ]. Many studies has been carried out merge kbs and hypermedia technologies, such as ExperText [ Rada & Barlow 1989 ], HRExpertext [ Diaper & Rada 1991 ], DataLex [ Greenleaf et al. 1991 ], Animated Hypertext [ Bench-Capon et al. 1991 ], [ Soper & Bench-Capon 1994 ]. The distinction between kbh , ExperText and HRExpertext is that the first is built using open architecture approach. Whereas, the later two are built using integrated approach and are close systems. End users can not add new functionalities to fulfil their future needs. The similarity between kbh and the models proposed in [ Greenleaf et al. 1991 ], [ Bench-Capon et al. 1991 ], [ Soper & Bench-Capon 1994 ] and [ Schwabe et al. 1990 ] is that all three are built using an open architecture approach. The model of [ Schwabe et al. 1990 ] differs mainly in having a uni-directional communication channel between component systems, designed for sending queries to the kb from hypertext. The model of [ Greenleaf et al. 1991 ] differs mainly as it is implemented in an imperative language and is a close system which does not allows end users to add new functionalities. The model of [ Bench-Capon et al. 1991 ] and [ Soper & Bench-Capon 1994 ] concerned the communication channel as bi-directional, and hence corresponds to our model of kbh , but it did not implement the direction in which the kbs sends messages to the hypermedia system. However, in the kbh framework the communication between component systems is bi-directional. Both hypermedia and kbs can send and receive messages to and from each other on a run-time basis and therefore can use the functionalities of each other for system level tasks. Another distinctive feature of the kbh frame is its modular based LP meta-programming approach for the development of kbs shell. In kbh , the kbs shell is a collection of different modules which are responsible of different tasks. All modules are developed using a meta-level programming approach and they communicate with each other through a message passing protocol. A central module, Message Analyser, is responsible of this communication. Message Analyser acts like a post master. It receives messages from other modules and sends them to the relevant modules. It also provides communication links between the BCC and kbs shell. The main advantage of our approach is that it keeps control knowledge separate from object level knowledge. So, any change in the kb does not affect the kbs shell. Also, it makes the shell open-ended allowing end-users to add new functionalities. At the same time, the kbh framework provides a communication channel between two systems implemented using two important language paradigms, imperative and declarative (specifically 'C' and Prolog - [ Fountain et al. 1990 ], a third party product implemented in C for Windows, is being used as hypermedia system and LPA Prolog for Windows is being used for kbs development). Therefore the framework allows users to use utilities written in either of these two paradigms. In the kbs shell we have tried to build a selection of fairly generic information management tools which can be available in the shell and are useful over a range of applications. Our main tool in this area is Proof tree based Conceptual Retrieval (PCR) as discussed in the next section. It should be emphasised that kbh is not a panacea for all problems with hypermedia. Its basic limitation is that it focusses on features of the unstructured hypermedia information base which are susceptible to formalised modelling in a knowledge base. Clearly there are hypermedia tools which do not rely on such models. For example navigational tools such as maps and histories and their extensions; pre-defined 'trails' through the information base; and statistical information retrieval techniques. While we believe that development of such tools is essential for practical hypermedia information management our claim is that they are basically complementary to the tools supported by kbh . 4. Proof Tree Based Conceptual Retrieval (PCR) An important requirement of conceptual retrieval is that it not only analyses conceptually the contents of documents, but also of user requests. Furthermore the adopted search strategies must be very flexible [ Dick 1987 ], [ Wildemast & de Mulder 1992 ]. Ideally a fully automatic system would achieve these goals - some of the current attempts are reported in [ Mulder et al. 1993 ], [ Mulder & Combrink-Kuiters 1996 ] - but this approach faces serious problems. One way to alleviate the problems of automation is to aim for a semi-automatic method, in which machine and human work together during document storage and retrieval. The advantage of a semi-automatic method is that the human can guide the system for retrieval. We believe that this is a flexible and practical method. It puts an extra overhead on the human but the retrieval will be more effective and more meaningful. To provide conceptual retrieval in hypermedia, we have developed a semi-automatic technique called P roof-tree based C onceptual R etrieval (PCR). PCR is an LP based kbs technique. It exploits four important features of logic programming: Horn clause logic, Query-the-User (QTU), proof trees, and meta-level programming. The main idea of PCR is to build a dictionary of general concepts from a particular domain by formalising their definitions as Horn clauses using simple available knowledge. Using these definitions, the system extracts conceptual information from documents and from users by running appropriate logical queries. During the query evaluation process the system asks users about any missing information needed to satisfy the definitions. There are two distinct, but closely related, situations when PCR comes into play: during an interactive dialogue with the kbs the user may request to see relevant documents ( retrieval situation ); when entering a new document into the system it needs to be labelled ( labelling situation ). In the retrieval situation, users provide the system's requested information according to their current circumstances. In the document labelling situation, users provide the information from the contents of the document. At the end of this interactive session, the system generates a proof tree (execution trace) of the processed query using the supplied information. In the labelling situation , the system uses the proof tree to label the document from where information is being extracted and stores this information as a proof tree label in the Label Base for future retrieval. In the retrieval situation , the system uses the proof tree as a source of conceptual information about the users retrieval request and by matching proof tree labels from Label Base, the system finds documents having similar/relevant information. It is important to mention here that a proof tree, in our sense, is defined in term of the derivation trace produced when a query is evaluated. We use proof trees as conceptual labels because they contain information about how a query is solved and which rules and facts were used during the evaluation process. Also Sergot [ Sergot 1991 ] mentioned, in LP a proof tree is not merely a trace of computation but logical proof of any conclusion reached. The overall purpose of PCR is to find relevant documents, and the basic idea is to do this by matching proof tree labels. We have designed a proof tree label matching algorithm: by matching predicate names of the proof tree nodes, the algorithm generates a single number ( matching weight ) as a measure of similarity between two proof tree labels. The system then generates a percentage matching weight which is used to give a clue to users about the level of relevancy between retrieved documents and their request. (Detailed account of PCR is given in [ Soper & Pasha 1994a ], [ Pasha & Soper 1995 ], [ Pasha 1996 ].) 5. Retrieval Using PCR in Legal Domain In this section we illustrate how PCR can meet the legal professionals' needs of precise retrieval in the kbh framework. Figure 3 shows a simple definition of the concept entitlement to registration , derived from the leaflets,[ Home Office 1991a ], [ Home Office 1991c ], [ Home Office 1991b ] formalised as Horn clauses. It shows that a single concept has many eligibility conditions which an applicant might satisfy. The legal domain offers many sources of information such as text books, commentaries and case reports. Taking the example of case reports, hundreds of case reports are available about this concept which certainly have different factual information depending on the clients' situations. As mentioned before, linking all available case reports to a single concept, using the hypermedia linking facility, could create retrieval and navigational problems as it does not allow splitting information into different groups. PCR overcomes this problem. For example suppose a user selects the concept entitlement to registrantion from a document to link a case report having information about a person who is a British Overseas citizen and satisfies the residence conditions. (A concept could be a word, phrase, or a sentence.) The system allows users to link a logical query from the kb with its corresponding concepts. The system then runs the query associated with this concept. During the query evaluation process, the system will use the first definition about British Dependent Territory citizen, and will query the user with Does document have information about British Dependent Territory citizen? Certainly the user will say `no' - as the document does not have such information - so the definition fails. The system will pick the next definition, about British Overseas citizens, and try to satisfy it by querying the user. In this case, the user will say `yes' as the document is about a British Overseas citizen. Now the system knows that the newly entered document is about British Overseas citizen. In this way the system will extract the conceptual information about the document. At the end of the interactive session the system will generate a proof tree of the current session using the supplied information and use it as a label for the new document. The system tags the proof tree to the body of the link and stores it in the Label Base in the form: The new document is now linked with the selected concept. Once this information is stored into the Label Base, it is available for future conceptual retrieval. This is an indirect method for the system to extract conceptual information from newly entered documents. During a navigational session, if a user wants to see particular information about the concept, the system will use the query associated with this concept and try to satisfy the definition. In this case, the user will reply to questions according to their current interest. This is an indirect method to extract conceptual information about users' interests. The system also asks about the required type of the document. Figure 4 shows a retrieval request for case reports having information about 'residence requirements'. At the end of the interactive session the system generates a proof tree label using the supplied information. A matching algorithm then allows matching/relevant proof tree labels from the Label Base of the required document type to be found and the associated relevant documents retrieved. The system displays retrieved document titles along with their level of similarity to the required information in rank order (see Figure 5 ). Users can see a summary of the selected document first, before seeing the whole text via hypermedia. The system generates this summary automatically using information stored in the Label Base. The summary gives a conceptual picture of the retrieved document (see Figure 6 ) and provides rich enough information about the document to make selection easier and also, possibly, to save users from reading the full text. PCR offers two main advantages: (i) it dynamically retrieves the documents which are conceptually similar to a user's request; (ii) it substantially eliminate the problem of irrelevant retrieval. Another notable thing here is that from Figure 3 it can be seen that the definition of this top level concept, entitlement to registration , has information about many other lower level concepts, such as meets residence conditions, satisfy crown service conditions , etc. This shows that a case report having information about the top level concept also has information about many lower level concepts. In a hypermedia system, authors need to build links explicitly between lower level concepts and the documents having information about the concepts. Whereas with PCR a document linked with a top level concept can be retrieved dynamically from any lower level concept about which it has information. For example the proof tree label of a query related to the concept meets residence conditions will be a part of the proof tree of the query related to top level concept entitlement to registration . So using the matching algorithm, the system can retrieve the document entered using this top level concept rather than its lower level concepts. This means that a new document, having relevant information about a top level concept, brought into the system automatically, contains links about its lower level concepts. This feature of our technique provides a strong basis for reducing the manual linking overhead of authors. 6. Enhancing PCR with Conventional Database Retrieval Techniques Providing a facility for conventional database retrieval would not normally be claimed as a big achievement, but combining such structured retrieval with PCR brings together two complementary retrieval ideas and appears to produce a considerably more effective system. For example, by just giving the case number, the enhanced system can retrieve as well cases which are conceptually relevant to this particular case. During the labelling situation , through a dialog box, the system ask for structured information about a newly entered document and stores it in the Label Base in the form: caseInfo(appellant(Name), respondent(Name),courtName(Court), Once the labelling information is stored into the Label Base, it is available for conceptual and structured retrieval. Users can ask the system for structured retrieval through a provided option. If users do so, the system displays an editable window through which users can enter a search key. Given a search key, the system uses a simple pattern matching technique to search the Label Base for matching entries. If the system finds a matching entry, it picks the proof tree label of this entry and starts matching it with other proof tree labels in the Label Base. By matching proof tree labels it finds other relevant documents. So the system automatically retrieves documents relevant to that particular document. Figure 7 shows a retrieval set of a user request for [1993] Imm AR case report. This shows the potential of PCR when combined with data base techniques. We believe this feature will be very useful for law professionals who, for example, sometimes wish to retrieve relevant cases with respect to particular factual information. 7. Meeting the Integration Needs to See the Practicality of Information In this section we show how the kbh framework meets the need for integration by allowing the practical use of the available information. We briefly describe our prototyped system developed using leaflets about British Nationality registration provided by the Home Office [ Home Office 1991a ], [ Home Office 1991c ], [ Home Office 1991b ] . These leaflets contain a simplified exposition of law for the general public and advice workers, so that they can get a general understanding of the issue. On the one hand, the information given in these leaflets is not rich enough to apply the law properly. On the other, repetition of information, heavy use of cross references, and the presence of open texture concepts makes the leaflets unwieldy [ Bench-Capon et al. 1991 ]. kbh provides a basis to over come these problems. Using the hypermedia linking facility, the problems of cross references and repetition of information is being handled. Using kbs and PCR facilities an advisory system type of environment is being offered in which users can see the practicality of the information and can retrieve conceptually similar information to their request. In our prototype, text from these leaflets is stored in different hypermedia documents. The documents are linked through the hypermedia manager's linking facility which creates an environment in which information from different leaflets is available as in one body. The kb contains definitions of important concepts from the leaflets. These definitions are taken from the text of the leaflets and formalised in Horn clause logic. Using PCR some hypothetical cases, and some actual cases (stored as text files), have been linked with some important concepts. The prototype allows users to attach available logical queries from the kb to their corresponding concepts. The attached queries can be run for two purposes; conceptual retrieval and to see the practicality of the information. In the later case the system will evaluate the query and display the results from kbs shell's user interface. For example, the user can see whether he/she is entitled to registration or not. At the same time he/she can ask the system to show relevant information to this particular concept. This is a powerful active document feature. It allows users to see the practicality of the available information within hypermedia documents. 8. A Flexible Approach to Handling Open Texture Concepts In the kbh framework, using PCR, we have designed a help facility which can be brought into play during a QTU session so as to explain the system's questions. Many approaches have been proposed in the literature for providing help during QTU sessions. Wolstenholme [ Wolstenholme 1989 ] proposed that if users do not understand a question posed by the system, then the system asks a simpler question declared at the meta-level. These simple questions should not be the part of object program. This is a good suggestion, however, some issues need clarification. For example: Who will decide which question is difficult? Should simple questions be attached with every ask able question? The problem of users not understanding a question often occurs in relation to open texture concepts. So a particular issue is designing simple questions for these concepts. By their nature such concepts can not be formalised adequately. So what sort of information or simpler question should be provided? A commonly used approach is to attach a text/hypertext file, such as case reports , to each open texture concept so that users are helped by reading this information [ Schild 1989 ]. This is rather inflexible since it hard-wires relevant information to concepts. The system needs changes if new information arrives related to a concept. To provide help about open texture concepts during a QTU session we took a different approach. We display documents in which the concepts being asked about have been explained. This can help users to understand the concepts. In our approach the connections between relevant information and concepts are not hard-wired, rather the system computes it on the fly. So our system provides a flexible environment in which users can add new information easily. Detail discussion of our approach is given below. In our prototype we use Kowalski and Sergot's approach [ Kowalski & Sergot 1990 ] leaving the open texture concepts undefined in logical models. For example, the concept applicant has special circumstances is an open texture concept. It is hard to formalise this concept. In our prototype, during a labelling session when the system asks the question An important point to mention here is that a case report related to a particular issue would also have information about other relevant minor issues. For example, from Figure 3 it can be seen that a case report about the major issue entitlement to registration would have information about other minor issues which need to be satisfied to solve the major issue. In our approach a case report linked with a major issue will automatically acquire links with all the considered minor issues and could be retrieved during a QTU dialogue session. The system computes these links dynamically. This certainly reduces linking overhead and offers more flexible approach than attaching text files directly with each minor issue. We believe this is a good approach to handling these open texture concepts since the system provides maximum information to users and leaves it up to them to interpret the meanings of the concepts and to take any decisions. In this paper we have examined some limitation of hypermedia systems for handling legal information. Then we proposed a general framework, kbh , for loosely coupling hypermedia and kbs which allows kbs information management tools to be developed so as to address the limitation of hypermedia. We proposed a general tool for conceptual retrieval, PCR, which labels documents according to their conceptual content in a semi-automatic manner. We showed how this tool works in the legal domain taking the retrieval of case reports as an illustration. We also showed how PCR provides the basic infrastructure to address three needs of legal professionals. The need for precise retrieval is supported directly by PCR and becomes a practical when enhanced with database retrieval. The practical use of unstructured information relies on the same idea. It supported by allowing interactive dialogue with the kbs which generates a PCR label. Finally we addressed the question of open texture in law. Again PCR provided the means to retrieve information which would help the user's open texture interpretation at the appropriate point, during query-the-user dialogue. One direction for future research will be to explore further the usefulness of the kbh information management tools described in this paper. We would like to develop a realistic application, probably in the legal domain, and evaluate our system in relation to other approaches such as case-based reasoning systems. A key aspect will be to evaluate under practical conditions the claim that our system can deliver more precise retrieval than conventional methods.
|